Git Serie: Part 1 Git Basics
This post is the first part of a serie that will help you better understand Git in order to use it in a more efficient way.
Git is what we call a Distributed version control and source code management and has been developed by Linus Torvalds the creator of Linux. Git allows developers to keep a history of their code, to manage the development of various features in parallel, to change the development’s history and most of all Git makes it possible for hundreds of people to work on a same project from different locations around the world.
Many people using Git are not aware of the possibilities it offers them. They restrain their use of Git to backup their code and merge some branches without really understanding the whole mechanism behind it.
This is what you’re going to learn with this serie of posts. So let’s first have a look on how Git works.
Git saves snapshots
Git as opposed to its predecessors (such as Subversion) doesn’t save the difference between 2 successive commits, it doesn’t use deltas, but instead takes a snapshot of all the files under version control. Thus each commit contains the whole project at a given moment. Yet, to spare some space, Git uses references to the previous commit for the files that didn’t change between 2 successive commits.
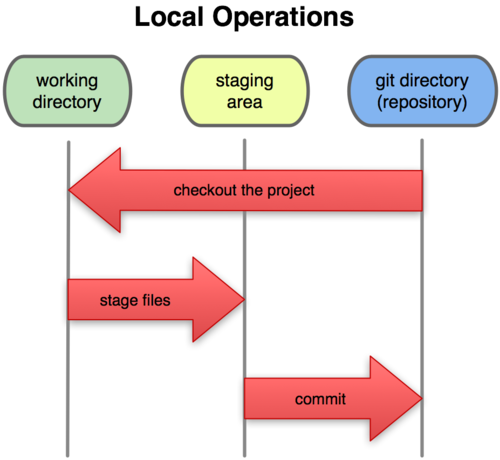
The three states
Files that are managed by Git are called tracked files. Tracked files can be in 3 different states:
- Modified/Unmodified files in the Working Directory
- Files whoses snapshots are ready to be commited in the Staging Area
- Commited files in the Git Directory
To know in which states are your files use the command git status.
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: FOSUserBundle.php
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: FOSUserEvents.phpBranches are references
Now that we have seen how Git saves and manages files modifications let’s concentrate on branches which is the most important feature of Git and also one of the features that people understand the less.
Before Git vcs like Subversion were also using branches. To create a new branch from an existing one, Subversion had to copy all your previous commits into the new branch. It was a heavy process consuming a lot of space and time.
That’s why Git uses a total different approach. In Git branches are nothing more than simple references.
Let’s create a foo directory and initiate a Git repository:
$ mkdir foo
$ cd foo/
$ git init
Initialized empty Git repository in /Users/john/Prog/git/foo/.git/Add some dummy files and commit them:
$ touch bar foo
$ git add .
$ git commit -m "Initial commit"
[master (root-commit) a4faf01] Initial commit
0 files changed
create mode 100644 bar
create mode 100644 foo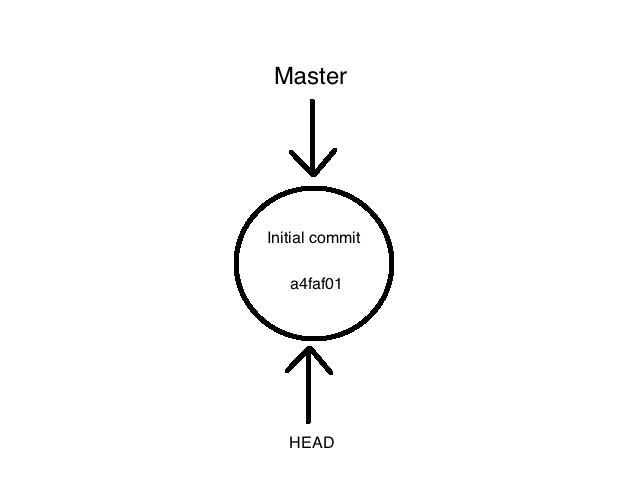
The drawing above shows us that the branch master is actually a pointer on our first commit whose abbreviated sha1 is a4faf01. We can also see that HEAD is a pointer on our first commit. HEAD represents our position in Git, it’s what we are pointing at right now.
Let’s just add another file and create a second commit:
$ touch ipsum
$ git add ipsum
$ git commit -m "Second commit"
[master 650a70c] Second commit
0 files changed
create mode 100644 ipsum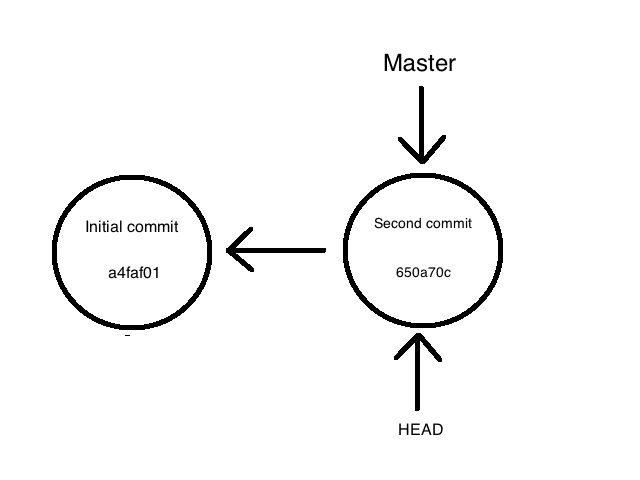
We can see that now HEAD and master are pointing on the new commit 650a70c, and that this second commit is itself pointing on our first commit.
At this point a common error is to think that the branch master contains the 2 commits. This is absolutely false, as I said already branches in Git are nothing else than pointers.
To prove it let’s take a look at the hidden folder .git which is located at the root of our folder foo.
$ ls -l .git/refs/heads/
total 8
-rw-r--r-- 1 john staff 41 28 aoû 23:16 masterThe folder .git/refs/heads contains all the local branches of your repository.
Use the unix command cat to print the content of the branch master
$ cat .git/refs/heads/master
650a70ca3e3b8f3c554402a3747189dda4cf3dd6What a surprise! The branch master contains only one line, which is the sha1 of the second commit. That is exactly what we said, the branch master is simply a reference on the second commit.
And what about the HEAD? Let’s print its content as well
$ cat .git/HEAD
ref: refs/heads/masterWe see here also one line which this time is not a sha1 but a reference to the branch master. HEAD points to master which points to the second commit.
Let’s create a second branch and see what happens.
$ git branch dev
$ git checkout dev
Switched to branch 'dev'
$ touch lorem
$ git add .
$ git commit -m "Commit on branch dev"
[dev af02d9d] Commit on branch dev
0 files changed
create mode 100644 lorem
$ ls -l .git/refs/heads/
total 16
-rw-r--r-- 1 john staff 41 29 aoû 00:43 dev
-rw-r--r-- 1 john staff 41 28 aoû 23:16 master
$ cat .git/refs/heads/dev
af02d9d08f376389283ecd7e37a3240d7e08db54
$ cat .git/HEAD
ref: refs/heads/devBingo! As we were expecting dev indeed points to the new commit and HEAD keeps a reference to dev.
If we do a git checkout to the branch master the reference in our HEAD will be ref: refs/heads/master .
Let’s finish by a question:
Do you think we would lost our last commit if we were deleting the branch dev?
Let’s try it right now!
$ git checkout master
Switched to branch 'master'
$ git branch -D dev
Deleted branch dev (was af02d9d).Oups! Our branch dev is gone, but what happened to our commit? The unix command ls -l .git/refs/heads/ shows us that the file dev has disapeared.
So let’s try to look somewhere else:
$ git ls -l .git/objects/
drwxr-xr-x 3 john staff 102 28 aoû 23:16 09
drwxr-xr-x 3 john staff 102 28 aoû 23:16 65
drwxr-xr-x 3 john staff 102 28 aoû 22:53 a4
drwxr-xr-x 3 john staff 102 29 aoû 00:43 ad
drwxr-xr-x 3 john staff 102 29 aoû 00:43 af
drwxr-xr-x 3 john staff 102 28 aoû 22:53 e6
drwxr-xr-x 3 john staff 102 28 aoû 22:53 ea
drwxr-xr-x 2 john staff 68 28 aoû 22:49 info
drwxr-xr-x 2 john staff 68 28 aoû 22:49 packThe 5th result looks familiar drwxr-xr-x 3 john staff 102 29 aoû 00:43 af (these are the 2 first letters from the sha1 of the commit that was on dev), so let’s see what this folder contains.
$ ls -l .git/objects/af/
total 8
-r--r--r-- 1 john staff 165 29 aoû 00:43 02d9d08f376389283ecd7e37a3240d7e08db54Seems like the rest of our commit’s sha1. Even after deleting the only branch where this commit was, we can see that it is still present in Git. If you’re still not convinced, try that:
$ git checkout af02d9d
Note: checking out 'af02d9d'.
You are in 'detached HEAD' state. You can look around, make experimental
....
....
HEAD is now at af02d9d... Commit on branch devWe are now back on the commit we thought was lost (Don’t pay attention to the message about ‘detached HEAD’ state, will see this in a next post).
And to prove you again that branches don’t contain any commit history but only point on one commit (that itself points to a previous commit, etc…) let’s try a git log command.
$ git log --pretty=oneline
af02d9d08f376389283ecd7e37a3240d7e08db54 Commit on branch dev
650a70ca3e3b8f3c554402a3747189dda4cf3dd6 Second commit
a4faf01c472b51c9f6363703e8595fef9926ae44 Initial commitConclusion
AS we’ve seen Git uses a very different approach than that used by other VCS like Subversion. Git branches are just simple references so:
- they are cheap to use
- you can delete a branch without loosing anything
Now you should have a better understanding of Git. If it still seems unclear to you don’t hesitate to read this post again and to try the examples in your terminal.
In the next post we’ll have a deep look on merge and rebase.

